📔论文笔记1-Hierarchical Text-Conditional Image Genertion with CLIP Latents
Hierarchical Text-Conditional Image Genertion with CLIP Latents
DALL-E2的核心,OpenAI在2022年4月公开的图像生成与编辑算法
三大核心功能:
-
由原图生成相似图像
-
两幅图像之间插值
-
根据语言对图像做出指定的编辑
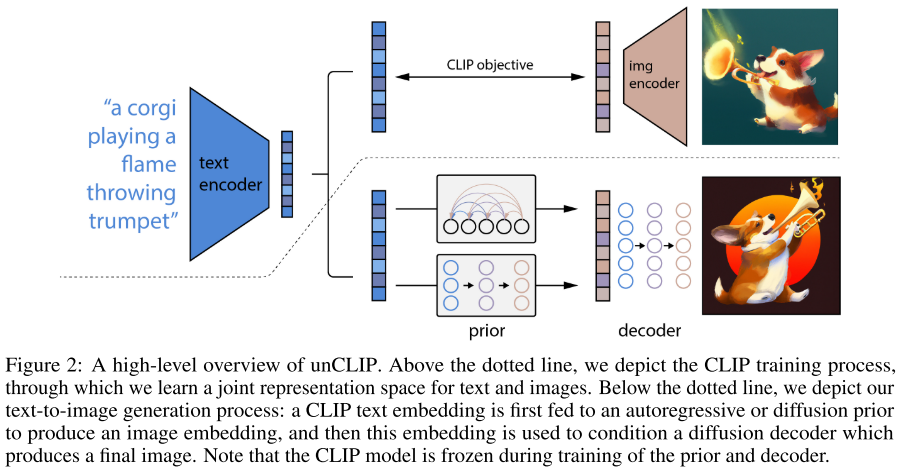
核心思想: 分两步生成图像,第一步称为prior,根据文字生成图像编码;第二步称为decoder,根据图像编码和可选的文字编码生成图像,使用了diffusion model。

为图像-文本对,为图像、文本的CLIP编码,这些数据被用于训练以上两个模型。
图像操作
给定图像可以获得隐编码,其中为CLIP编码,为使用decoder对应用DDIM inversion。
图像变体
获得隐编码时引入随机采样,获得在原图“附近”的图像

图像插值
两幅图像的隐编码间线性插值,而后解码出图象。为线性插值,的获取方式分随机向量(图像异于两幅原图)和线性插值(两端图像和两幅原图相同)两种。

文本编辑
根据文本的差向量旋转图像编码。文本差向量使用获得。

CLIP隐空间的探索
CLIP的隐编码虽然可能在排版攻击(typographic attack)下无法正确分类样本,但decoder恢复的图像可能不受干扰。说明编码确实包含了足够信息,只是分类器无法准确复原信息。
PCA重建可以发现CLIP编码包含了从高到低不同层级的语义信息。
文本到图像生成
尽管只用decoder部分就可以生成图像,但结合prior部分的unCLIP两步模型效果最好。
人工验证表明diffusion比AR更适合作为prior,而unCLIP比GLIDE在多样性上优秀很多。定性分析表明unCLIP比GLIDE在增加guidance scale(?)时表现更好。增大guidance时,unCLIP受的FID影响比GLIDE小很多。
unCLIP在MS-COCO上的FID获得了目前最好的zero-shot表现
艺术性比较,unCLIP也比GLIDE好
不足
物品和属性的绑定上存在困难,生成有文字的图像也存在困难
复杂场景下呈现细节比较难
包含不好内容