论文计划
目录
- 研究背景与领域介绍
(环环相扣!)
- 引入VLN的概念
- 概括几项经典的研究成果和发展方向
- 强调连续环境的研究还较少,也没有应用预训练模型的公开成果,提出第一个创新点:引入CLIP预训练编码器,内容可以写,但在引言中可能造成逻辑混乱,可以不着重强调
- 指出大部分研究忽视了语言指令的结构化特点,提出第二个创新点:分割子指令,理解更高层的语义(写得更充分,分割会带来什么好处,没有分割会导致训练或计算有什么问题。可能对语句的重点不够关注,或者给计算带来负担)
- 为了让模型更好地学习到关注单一子指令,提出一种损失函数:单峰注意力约束损失(如何更好地学习关注单一指令部分,提高准确性和高效的一个方面),根据情况,如果工作量足够可以考虑舍弃这个点
- 贡献列表
- 阐述方法
- 模型结构,包含问题建模的公式化描述和结构图
- 详细解释模型结构中的CLIP编码器
- 详细解释子指令部分的语言编码模型
- 详细解释训练损失函数
- 训练与实现
- 子指令划分的方式以及划分后的一些统计结果与评价
- 训练过程与参数
- 结果分析
- 横向对比,将效果最好的完整模型与以往研究成果和baseline对比
- 消融分析,各去掉三个部分后的模型效果,从baseline模型到完整模型逐步新增、替换模块形成不同复杂度的模型进行对比
- 可视化,成功例子和失败例子,子指令注意力
- 结论
- 模型是否达到预期,创新点是否有帮助
- 研究中还有哪些不足和没有探明的问题
- 未来的工作
*依靠逻辑引导读者思路
学长经验
- 周学长感觉ECCV比普通trans难,ECCV还两个多月,如果不着急发表时间来得及可以试试(希望不大)
- 颜学长:
- 找一篇核心参考文献作为样板,提炼结构,先写提纲,理清思路,再写中文,然后翻译润色
- 介绍是首先讲解决的问题,现有的主要思路,和你的思路与贡献
- 相关工作是讲参考的工作以及你提出方法的动机
看论文写法
周[Semi-supervised 6D Object Pose EstimationWithout Using Real Annotations]
- 标题。研究问题:6D位姿估计,亮点:半监督、无真实标签
- 摘要
- 第一句简提研究方向
- 第二句引出深度方法
- 第三句指出深度方法对标注训练数据依赖性强的问题
- 第四句提出自己的贡献
- 五六七句分点解释方法和原理
- 第八句总结实验效果和结论
- 介绍
- 第一段。介绍研究领域(6D物体位姿估计)以及传统方法,指出传统方法的缺陷
- 第二段。引出深度方法,没有详说,直接指出深度方法存在的问题(依赖大规模标注数据)
- 第三段。承接上段,为了解决缺少真实标签的问题,一些方法被提出。
- 第四段。引入半监督学习,是另一种解决方法。半监督学习逐渐流行,但在本领域研究较少。少量的方法的效果也并没有解决核心问题
- 第五段。提出本文方法,详述半监督方法和仿真数据的处理方法
- 第六段。仍然是方法,引入了注意力模块。最后总结了在不同数据集上的效果
- 第七段。总结贡献,细分领域的第一个工作、基于点云的半监督方法、基于注意力的网络、测评数据集上的实证效果
- 第八段。文章的组织结构
- 相关工作
- 6D物体位姿估计综述⇨深度方法⇨另一类深度方法⇨仿真数据方法⇨本文的使用
- 半监督/自监督学习综述⇨在本领域的应用⇨本文的使用
- 注意力机制综述⇨本文的使用
- 提出的方法
- 第一段。给出方法流程框图。
- 第一部分。详细解释半监督学习。先综述,给出损失函数公式(包含三项加和),而后分述每个损失项
- 第二部分。详细解释使用的网络结构,包含基于注意力的特征提取和姿态估计两部分,有公式化的描述以及框图绘制。
- 实验
- 测试的数据集
- 评价指标
- 实现和训练细节
- 在第一个数据集上做消融实验和分析,列了一个数据表格。首先解释表格里行列意义,而后逐个细说消融项的影响。有一些重要的项在陈述完数据后还要辅以机理分析,在注意力部分还可进行可视化。最后有一个小节
- 在三个数据集上与现有SOtA方法的效果对比。列了三个表格,每个数据集上除了陈述结果外还绘制了测试图。
- 总结
- 第一句简述方法和克服的问题
- 第二句讲半监督方法的组成
- 第三句讲半监督方法的原理
- 第四句讲版监督方法的作用
- 第五句引入MMD特征映射,用来提升网络效果
- 第六七句介绍注意力模块和作用
- 第八句总结实验情况
- 分段,最后记录两个未来研究的方向
一些细节
- 论文总共13.5页,内容10.2页。摘要和介绍占1.6页,相关工作占1.25页左右,方法占3.1页左右,实验占3.8页左右,总结占0.4页左右
- 参考文献75篇,参考文献后有几位作者的简介
- 摘要192个英文词
颜[Unsupervised Anomaly Segmentation Via MultilevelImage Reconstruction and AdaptiveAttention-Level Transition]
- 标题。研究问题:异常分割,核心点:无监督、多层图像重建、自适应注意力层级转移
- 摘要
- 第一句简提研究方向
- 第二句陈述传统方法的不足
- 第三句总述文章提出的架构
- 第四-十句解释方法
- 第十一句写实验结果,达到SOTA性能
- 介绍
- 第一段。研究领域、必要性、难点和本文的贡献
- 第二段。综述无监督异常分割方法,现有方法在物体异常方面存在不足
- 第三段。两种主流的解决方向,本文综合了两种方向的优势,克服了三个限制
- 第四段。详述本文方法的思路,列出四点贡献:提出MLIR架构、ALT策略、自适应ALT、实证效果。
- 第五段。论文组织结构
- 相关方法
- 研究背景、难点以及最经出现的无监督思路。针对现有方法的不足,本文提出了新思路
- 第一部分。无监督异常分割,基于重建⇨基于特征
- 第二部分。图像重建,异常分割任务类似于图像修补,顺带提到本文加pepper noise的做法,感知损失以及本文的使用
- 第三部分。重建不确定性估计,以往的蒙特卡罗方法⇨本文基于贝叶斯相似原理使用特征方差建模重建不确定性
- 方法
- 先画框图并解释
- 第一部分。图像生成器,基于conditional GAN的模型,以及四个训练损失,是算法框图的前半部分
- 第二部分。异常分值图重建,包含感知重建误差、注意力层级转移和重建不确定性,是算法框图的后半部分
- 实验
- 实验的数据集、评价指标以及训练条件
- 消融分析,分别对噪声(不同类型与不同信噪比)、生成器、感知测量验证、重建不确定性进行分析,还给出了前向计算的时间比较
- ALT分析,强调合适的γ很重要
- 自适应ALT,如何自动获取较好的γ
- 与基线方法的效果对比
- 应用和未来的研究
- 总结
- 第一句提出的方法和解决的问题
- 第二句结构的概貌
- 第三句建模
- 第四句克服一种缺陷的手段,使用特征级的重建误差
- 第五-八句,提出的自适应ALT方法是如何利用不同层级的重建误差来对应对不同类别
- 最后两句总结实验和效果
一些细节
- 论文共12页,内容10.4页,摘要和介绍1.7页,相关工作1.3页,方法2.5页,实验4.6页,总结0.25页
- 参考文献48篇
- 摘要217词
模型实现需要做的事
- 数据预处理
要做两个数据集,因为不确定会不会有编码不一致的问题。两个集先做好,优先试第一个,效果不好再试第二个
- glove词表原指令与CLIP符号化的切分子指令
- CLIP符号化的原指令与切分子指令
还有一个分歧,到底要不要使用我自己写的规则切分,需要测试 - 只用nltk切分句子,
- nltk切分后再用我写的规则切分
- 模型实现
-
RGB:使用CLIP编出512维向量,经一层线性+激活降到256维
-
DEPTH:使用ResNet编出2048维向量,经一层线性+激活降到256维
-
RGB与DEPTH拼接,输入第一个GRU,新的状态向量对LSTM编码后的词向量做注意力,获得低层指令编码
-
RGB与DEPTH拼接,输入第二个GRU,新的状态向量对CLIP编码后的子指令向量做注意力,获得高层指令编码
-
低层与高层指令编码相加获得融合了视觉的指令编码
-
指令编码对视觉特征做注意力,获得融合了语言的视觉编码
-
前两个GRU状态、指令编码、视觉编码共同输入到第三个GRU,输出动作分布
记得留消融分析的接口以及动作编码的接口。

在实现过程中对指令关注视觉的注意力模块产生疑问。感觉单层投射还是不足以满足需求,需要按照源码的方式再做一次注意力。
调试看了下,CMA的RGB编码后是[bs, 2112, 16]的特征,DEPTH编码后是[bs, 192, 16]的特征,因此可以做一维卷积。
两个问题:一维卷积获得k与线性映射获得k有什么区别?如何拿到ViT更低层的特征? -
尺寸为1的一维卷积与无偏置的线性映射本质一样,源码应该只是为了方便操作不做permute。我也参照这个写法好了
-
对clip_model.visual.transformer注册前向钩子可以拿到非最终层的视觉特征。原始的特征太长了,有768*49维,准备做一个meanpool降一下维。降到了3x3
depth原来输出特征是128*4*4也就是2048,如果使用空间输出那么每一个位置会被连接一个位置编码变成192*4*4,平滑化之后就变成3072了。重要改动,源码载入的深度特征仍为128*4*4,位置编码层并未得到训练,因此不可用!深度特征提取器的位置编码是需要训练的
加上视觉注意力的模型图为

-
实现单峰注意力损失的方式:构造一个高斯分布和注意力分数计算均方误差损失。直接在policy内部实现即可
-
实现inflection weights的方式:~~比较预测动作与真实动作,若不同则把actionloss乘以一个系数。在base_il_trainer的_update_agent中实现。~~源码已经实现了inflection weights,在config.IL.use_iw可以控制
-
发现一个非常影响效率的操作。之前为了抑制误差,对图像的处理使用的是for循环遍历batch维度而后使用torchvision的变换。以此为基点顺便比较了一些计算环节的耗时情况
- 调试环境下for循环 vs 张量减、除
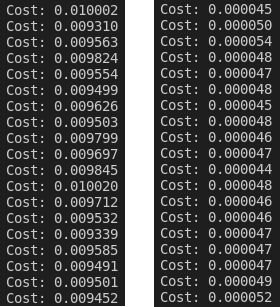
- 非调试环境下for循环 vs 张量减、除
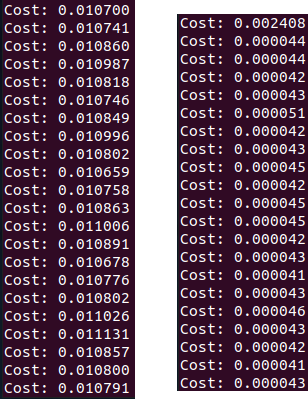
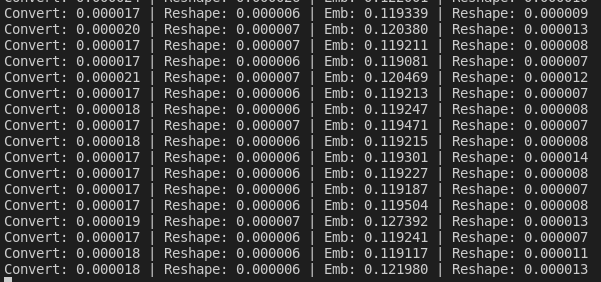
结论是调试环境和运行环境测试耗时相差不大;for循环太慢了,耗时是张量操作的近200倍。。 - 各编码环节的耗时

似乎瓶颈是提取子指令特征,得想办法加速一下
先做好全零张量,而后遍历batch只计算非填充的部分,把结果填入全零张量合适的位置。目前只加速了不到0.02秒。这个操作修正了一个错误,可以让填充子指令的位置真正返回全零(全零指令经transformer编码后并非全零)
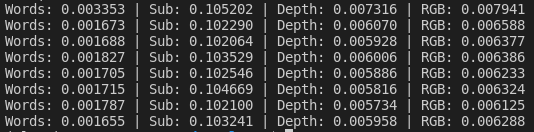
如果使用simple切分指令集,速度会快上很多
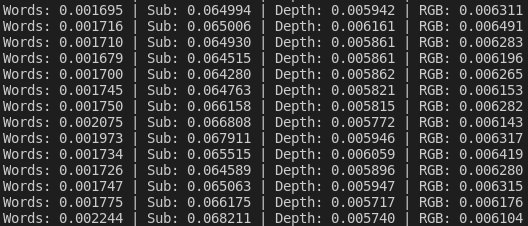
- RGB编码耗时详情

- 使用simple切分集时前向传播耗时统计
- c1: all embedings
- c2: all features pre projection
- c3: vision feature compression
- c4: state encoders
- c5: V2I attention
- c6: I2V attention
- c7: feature compression
- c8: action decoder
- c9: aux loss
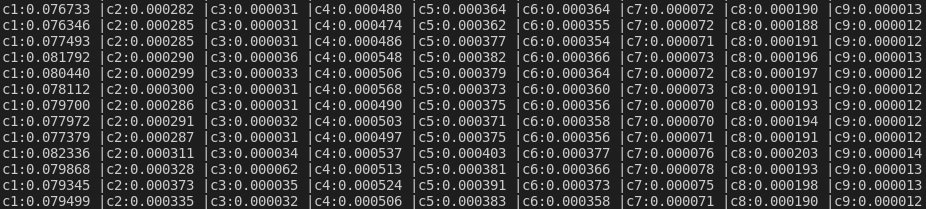
总耗时大头是编码,编码耗时大头是子指令编码
- 调试环境下for循环 vs 张量减、除
- Dagger训练or Recollect?
- 用dagger的话,需要保存指令tokens,子指令编码,图像编码,深度编码,即使上增强数据集文件大小应该也可以接受
-
消融分析?
-
记录下各个设备在做的事情,避免搞乱了
- 服务器正在eval mla1
- 主机正在eval mla3
- 在服务器训练并测试seq_wclip
- *在服务器上训练cma_wclip
- *在主机上再次训练seq和cma,用来比较
旧实验的结果

时间规划
看三篇文章(周,颜,顶尖期刊),然后动手写
论文时间点
2021.12.24
目录和老师讨论目录
2021.12.27
模型规划计划好要实现和训练的模型,并开始实现,启动撰写论文
2021.12.29
组会总结实现过的模型内容,绘制要实现的模型图继续模型实现
2021.12.31
训练完成实现,开始训练模型
2022.01.03
论文论文介绍部分初稿
2022.01.05
组会总结训练效果,论文第二部分初稿
2022.01.10
论文论文整体结构搭好,待修改、插图、实验